Factor graph学习
1. Third-Order Factor graph
1.1 图的介绍
Factor graph包含两种node:
variable node
- 表示individual action: V_y=i, {1,…,n},假设共有n个individual
- 表示a pair of individuals存在interaction的可能性: V_z=(i, j), {n+1,…,n+Cn2},n个individual理所应当有Cn2个组合
factor node
F_y={ (i, j, g(i, j) ) | ∀i, j ∈ V_y, i < j}, {n+Cn2+1,…,n+2×Cn2} ;
作用:implicitly model 两个V_y的base features和V_z的base feature的关系
F_z={ ( g(i, j), g(i, k), g(j, k) ) | ∀i, j ,k ∈ V_y, i < j < k}, {n+2×Cn2+1,…., n+2×Cn2+Cn3} ;
作用:implicitly model triplet of people(i,j,k)
关于连接两种node的edge
edge连接factor node和variable node(必须一端是factor node,另一端是variable node)
具体理解:如果individual one和individual two有关联,生成variable node:action variable(y)=a、b, interactive variable(z)=g(a, b); factor node:F_y=(a, b, g(a, b)), F_z=((a, b),(a, c),(b, c)),那么edge就应该是图1中green solid lines

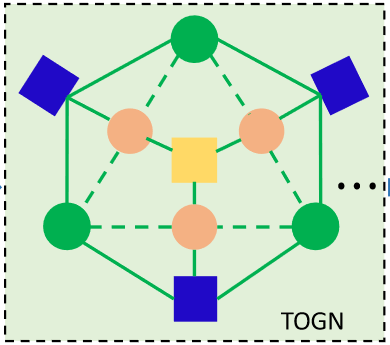
图1 TOGN(三个individual)
1.2 图的构建
图的构建主要两部分,一部分是initialized base feature(被送进第一层TOGN的,利用图特性来传递更新),另一部分是图的structure,即索引构建(如何对无序的initialized base feature建立关联性)
这部分主要解释索引构建
首先建立索引n+2×Cn2+Cn3个条目(代码里是从0开始索引)
索引条目可分为四个part,对应四个node类型:V_y、V_z、F_y、F_z
1 | n[0,n-1],(variable node-y) number=n |
For example:
1.从variable node-y到variable node-z
假设有5个individual,即n=5个(variable node-y),V_y={0,1,2,3,4}
1 | h_id={ c:i+N for i,c in enumerate(combinations(range(N),2))} |
如下图,n个individual进行二元组合,得到10个variable node-z;
以dictionary的key-value形式存储,key=(i, j),value=索引(在整个索引条目中的位置);
ps1:因为V_y={0,1,2,3,4}占据了索引条目中index: 0-4,,V_z排在V_y后面,就从index=5开始
ps2:这张图仅为Graph构建前提,不是Graph本身
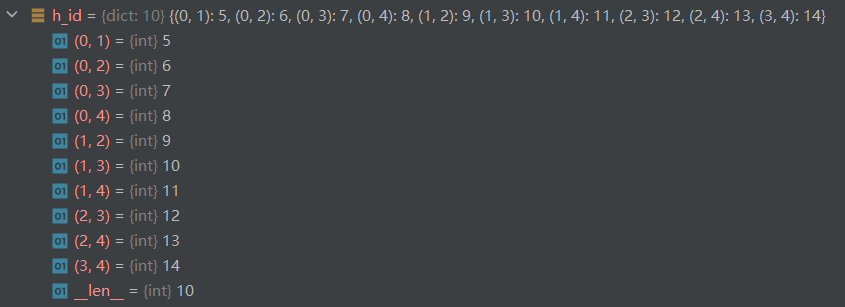
2.构建Graph
Graph-G索引本质上是一定数量的list(共n+2×Cn2+Cn3,有多少node,就有多少list),对应了所有类型的node,即V_y、V_z、F_y、F_z四个part。
1 | G=[[] for _ in range(N+N*(N-1)+N*(N-1)*(N-2)//6)] |
问题:这些list的内容是什么,即每个node存放什么
举例子:
factor node-y=(i, j, g(i, j)),在Graph索引中factor node-y的起始位置为hidx=n+Cn2(前面是V_y、V_z的位置),那么G[hidx]=????,即i=? j=? g(i, j)=?;G[hidx]=[u,v,h_id[(u,v)]]
若n=5(总共有5个人),在G中,第一个factor node-y的位置hidx=15,G[15]=[0,1,5];
因为根据从variable node-y到variable node-z部分的解析,5个人两两组合,得到key=(0,1)(0,2)..(individual one索引,individual two索引)…(3,4),value=5、6..individual combination在G中存放位置..13、14,总共10个key-value存储数据((两层for循环是按顺序组合5个人,第一个人的索引=0,第二个人索引=1))
那么F_y存储的就是(individual one索引(u),individual two索引(v),combination在G中存放位置(h_id[(u,v)]) )
————————————————————————————————————————–>
那么variable node-y和variable node-z存放什么?
1.variable node-y存放factor node-y的索引;
假如individual one索引(u),individual two索引(v)构成了一个factor node-y,该F_y的位置是G中第hidx个list—->G[hidx],那么G[u]=hidx,G[v]=hidx
ps1:一个人可以构成很多个F_y,例如第一个人(index=0),可以构成factor node=(0,1,5)/(0,2,5),则G[u]存储的hidx是所有与点u有关的F_y的索引
ps2:第u个individual实际会参与N-1个variable node-z构成,即G[u]:N-1个factor node-y的编号
V_y: ‘all’ related labels of F_y
2.variable node-z存放factor node-y的索引;
同理,跟V_y存放内容一样,V_z存放与自己有关的F_y的索引
1 | hidx=N+N*(N-1)//2 #factor node-y的起始label n+Cn2 |
如下图,
0-4代表V_y:存放related index of F_y
5-14代表V_z:存放related index of F_y
15-24代表F_y:存放index of V_yu V_yv and F_y
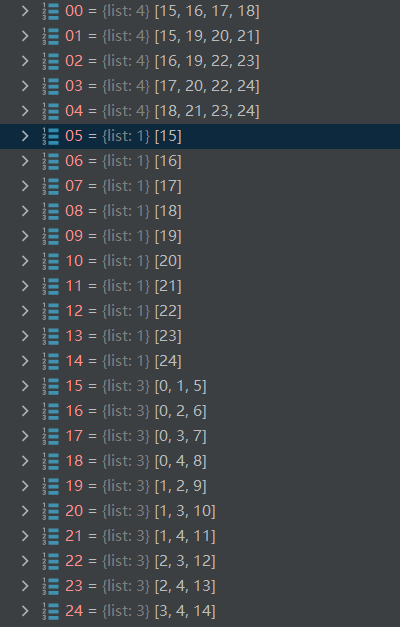
————————————————————————————————————————–>
剩下factor node-z存放什么还不知道????
factor node-z=((i,j), (i,k) ,(j,k)) 的索引从gidx=n+2×Cn2开始,G[gidx]=[z1,z2,z3]
ps:(i,j)指的是两个individual组成的V_z的索引
假如n=5,gidx=25,G[25]=[5,6,9];
因为individual one索引=0,individual two索引=1,individual three索引=2,组合得到(0,1)(0,2)(1,2),根据1.从variable node-y到variable node-z图中可以得知,h_id[(0,1)]、h_id[(0,2)]、h_id[(1,2)]分别对应5、6、9(三个V_y组合成的三个V_z在G中的索引位置)
为了保持关联性,G中V_z的位置要添加F_z的索引gidx:G[z1].append(gidx)、G[z2].append(gidx)、G[z3].append(gidx)
1 | gidx=N+N*(N-1) #factor node-z的起始label n+2*Cn2 |
V_z: related labels of F_y(only one) + ‘all’ related labels of F_z
25-34代表F_z:存放n(=5)个individual进行Cn3组合后,再Cn2组合得到的三个二元组(a,b)(a,c)(b,c)在G中的索引
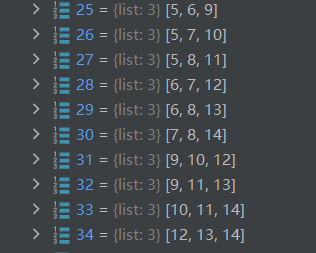
图 Graph中的factor node-z
5-14代表V_z:在存放了index of related F_y之后,存放index of related F_z,比如index=5代表的(0,1)组合,总共5个人,除去0, 1还剩3个,(0,1)作为整体和剩下三个组合,得到3个三元组,即三个F_z,那么index=5的V_z就需要关联3个F_z的index=25,26,27
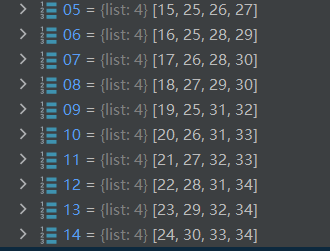
图 Graph中的关联factor node-z后的variable node-z