covlution 学习
卷积层(convolution layer)
填充(padding)
作用:因为深度学习的模型里会有很多层cov layer,而每层cov layer都会让原来的图变小(比如,33×33的picture,用 5×5的kernel,会产生28×28(33-(5-1))的新picture)。为了不让picture在许多层cov layer后变得太小,就会在输入周围额外添加行/列

为了使输出的picture size 和输入相同,padding 的大小通常取kernel size-1(kh-1,kw-1)
步幅(stride)
一般为2的倍数,成倍的减少输出size
多通道
多输入
RGB图像就有三个通道,每个通道对应一个kernel(注意:RGB是三通道,可以看成一个feature map,H×W×D,深度不为1,filter可以看做是包含深度的kernel,而filter深度=feature map深度,即a×b×D,),结果是所有通道卷积结果的和
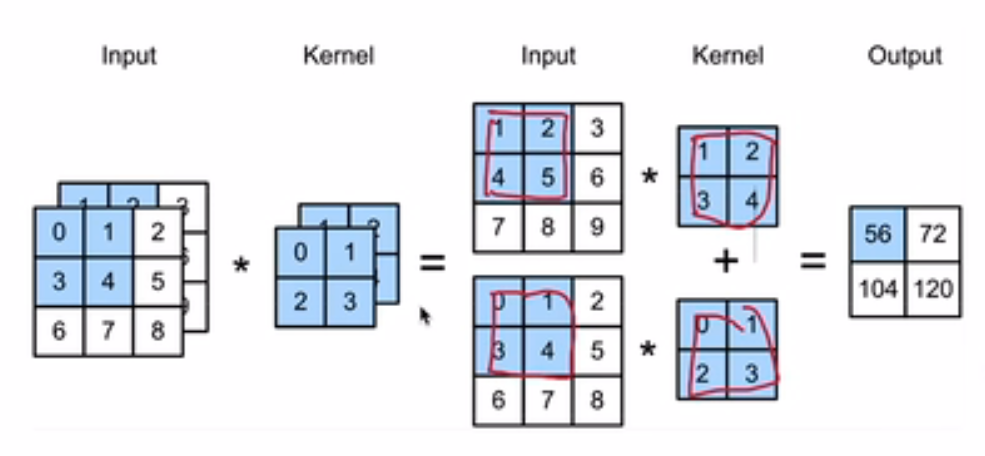
多输出
前提:多输出和多输入没直接关联性
多输出举例:RGB三通道(三个2维kernel==一个3维kernel)经过3维kernel,得到3个结果,然后求和(得到一个2维结果),如果对RGB图像,使用n个3维kernel,得到n个2维结果(一个2维结果就是一个3维kernel(一个filter)计算得到的)
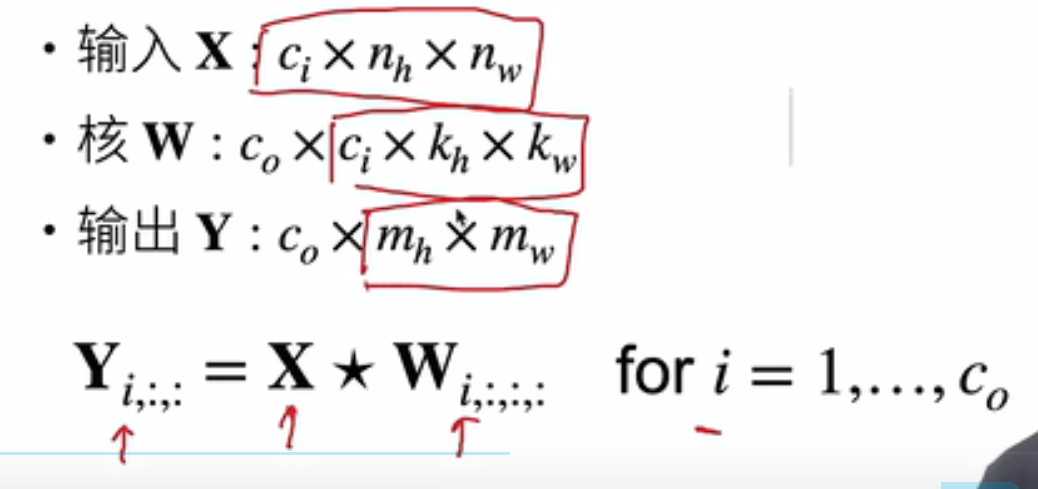
多输入和多输入结合理解
多输出通道:不同的kernel识别重点不同,比如有的输出猫头特征,有的输出猫尾巴特征
多输入通道:将输出通道的多个输出,进行权重相加,得到组合的特征
池化
缓解卷积层对位置的敏感性(一般放在cov layer后面)
二维最大池化(当然还有平均池化层)
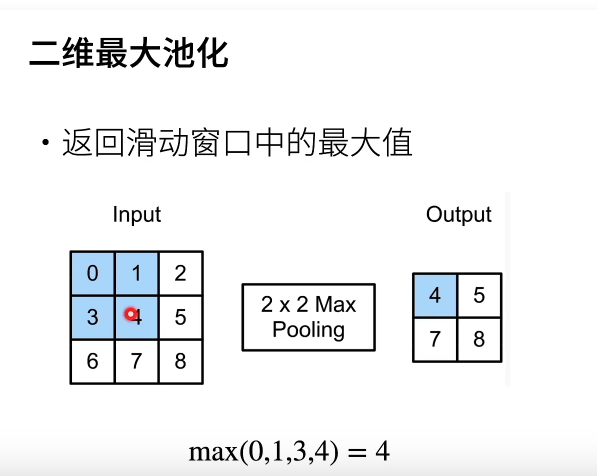
池化层也可以包括padding、stride;如果有多输入通道,每个input channel经过池化层后,直接得到输出(输出数量=输入通道数,不同于cov layer->将多输入卷积结果合成一个结果),因此,有输入->池化->输出(输入通道数=输出通道数)
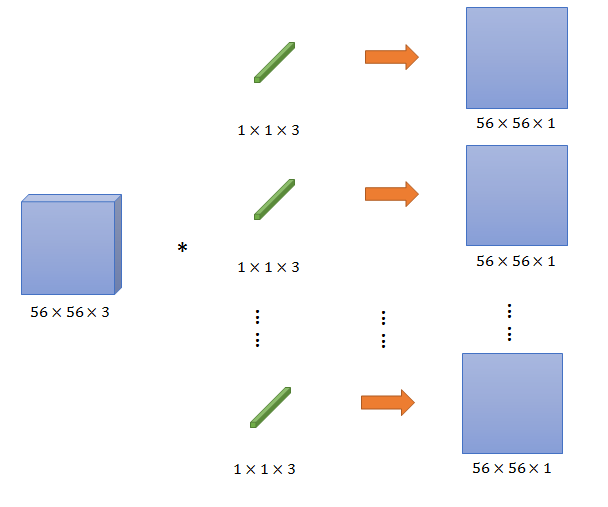
1×1卷积
升维/降维
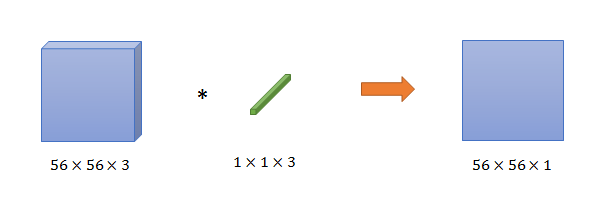
用一个<1×1×同feature map深度>的filter,对feature map卷积,可以将feature map深度变成1(注意:因为feature map深度为3,像RGB图一样,深度为3的filter(或者说3个1×1的kernel)卷积,是将对3个深度为1的56×56图卷积后,将结果线性相加的到深度为1的输出的);
用二个filter,可以得到56×56×2的结果(因为结果的深度都小于3,所以是降维)
用n个>3的filter,可以得到56×56×n的结果,是升维